

Ravi de vous retrouver aujourd’hui pour un nouvel article sur les bases d’HTML ! Si vous êtes déjà familier avec le concept de balises et celui des attributs, vous êtes paré pour découvrir la structure d’une page HTML. Avant de nous jeter dans le vif du sujet, je tiens à dire que pour que cet article reste assez léger, je ne rentrerais pas dans tous les détails volontairement. En effet, HTML est un langage parfait à bien des égards, y compris quand on veut se perdre dans les méandres des exceptions. Mes excuses par avance aux puristes qui liraient ces lignes et pour qui les détails ne seraient pas tous explorés ou décrits à la perfection.
Quel est l’interêt de la structure d’une page HTML ?
Nous allons prendre tout de suite les bonnes habitudes. En HTML, on ne parle pas de page. En effet, cet abus de langage provient du fait que HTML a hérité de nom de « page » consultée au moyen d’un navigateur, mais on parlera bien de document HTML.
Cette précision faite, on peut se demander pourquoi a-t-on besoin de la structure d’un document HTML ? Et bien, pour plusieurs raisons. D’abord parce que les navigateurs interprètent HTML en suivant un standard. Ce standard (sorte d’ensemble de règles définies) permet d’offrir un cadre uniforme d’exécution quel que soit le navigateur utilisé. Ce standard est rédigé maintenu par le W3C (le World Wide Web Consortium). Cette organisation a été créée par Tim-Berners Lee et il en est aujourd’hui le président. Elle regroupe de nombreux professionnels du web et a pour but de définir les normes des langages du web et de garantir un web uniforme.
Le W3C ne gère pas uniquement le standard d’HTML, mais travaille sur des dizaines de langages (CSS, XML), de spécifications (ARIA par exemple) ou même de formats de fichiers (PNG, SVG…). Les documents et les recommandations W3C qui sont formulées par le W3C s’adressent à deux types de public très différents :
- les concepteurs de navigateurs (Mozilla, Google, Apple, Microsoft…), afin que ceux-ci conçoivent des outils qui sont en mesure d’interpréter de manière uniforme le code, pour proposer une expérience similaire à tous les utilisateurs.
- les développeuses et les développeurs qui doivent également des normes et des recommandations pour que le code qui sera interprété par les navigateurs soit convenablement perçu.
En tant que développeur, votre rôle est de concevoir un document qui satisfasse à ces normes. L’une d’entre elles est de bien structurer son document HTML selon le standard choisit.
Quel standard HTML utiliser aujourd’hui ?
Et oui, il n’existe pas qu’un standard. Bien que certains ne soient plus amenés à évoluer, ils continuent à être normés officiellement pour la simple et bonne raison que des sites web (de plus en plus rares) existent encore avec d’autres langages qui ne sont pas tout à fait de l’HTML.
Pour simplifier, nous allons partir du principe que le seul standard auquel nous allons considérer maintenant dans le cadre d’HTML est celui d’HTML5. Cette version du langage lancée en 2014 a été enrichie jusqu’en 2017 (version actuelle : 5.2). Depuis, la version 5.3 est en cours de développement. Les buts d’HTML5 est d’ajouter des fonctionnalités, de nouvelles balises sémantiques et également d’uniformiser les deux branches HTML et XHTML pour rattraper le décalage qui existait entre XHTML 1.x et HTML4.
HTML5 vise aussi à simplifier certaines directives de document, notamment celle du <!DOCTYPE>, pour les rendre moins verbeuses.
Quelle est la structure d’un document HTML en 2023 ?
La structure minimale d’un document HTML valide W3C est la suivante :
<!DOCTYPE html>
<html lang="fr">
<head>
<title>Le titre de ma page</title>
<meta charset="utf-8">
</head>
<body>
...
</body>
</html>À la première ligne nous retrouvons la déclaration du doctype, comprenez le type de document. La balise est un peu particulière puisqu’elle est orpheline et commence par un « ! ». De plus doctype est toujours écrit en capitales. Après !DOCTYPE, on retrouve la DTD (la définition du type de document), qui est simplement html en HTML5. Le rôle du doctype est de « contraindre » le navigateur à appliquer les règles de la DTD spécifiée. Ainsi, cela indique au navigateur quel langage et quelle spécification de celui-ci va contenir le document.
À la ligne 2 on ouvre la balise <html> qui va contenir l’ensemble du document. Il est possible (et même recommandé) d’utiliser ici l’attribut universel optionnel lang qui précise la langue du document. <html> est décrite comme l’élément racine du document, en ce sens que c’est celui qui va contenir tous les autres. On remarque d’ailleurs que celui-ci est fermé à la toute fin du document. Tous les autres éléments du document sont contenu dans cet élément html racine.
Ligne 3 on ouvre la balise d’en-tête <head> du document, qu’on ferme ligne 6. Cet élément peut contenir de multiples éléments HTML de contexte qui sont liés au corps du document que nous allons voir. L’élément <title> en ligne 4 contient le titre du document, c’est lui qui est rendu dans le nom d’un onglet par exemple. Toujours dans l’en-tête, les balises <meta> permettent généralement de spécifier des informations qui accompagnent le document et fournissent du contexte. Par exemple, <meta charset= »utf-8″ /> permet de préciser le type d’encodage utilisé dans le cadre du document et éviter les caractères non reconnus. Les balises <meta> sont nombreuses et ne comportent qu’un attribut par élément.
Après avoir refermé l’en-tête du document, on ouvre le corps du document HTML ligne 7. Tout ce qui se situe entre la paire de balise <body> est destiné à être rendu par le navigateur visuellement. C’est ici qu’on trouvera le code qui nous permettra d’afficher des pages HTML.
Comment vérifier si un document HTML est valide au W3C ?
Pour nous aider à respecter le standard HTML, le W3C a mis sur pied un validateur qui est capable de détecter les erreurs éventuelles de notre document. Il ne réparera pas nos erreurs à notre place, mais il nous aidera grandement sur le sujet. Le validateur HTML du W3C est disponible ici. En arrivant sur la page, on peut choisir grâce à trois onglets la manière de soumettre notre document à valider :
- validate by URI : En indiquant le chemin vers le document, pratique pour une page déjà en ligne.
- validate by file import : En important le fichier .html à valider, pratique pour les gros fichiers HTML.
- validate by direct input : Ici, le validateur nous propose d’indiquer directement notre code dans un champ de formulaire.
Vous choisirez l’option qui se prête le mieux à votre cas de figure. En saisissant le code de notre structure de document HTML dans direct input, et en cliquant sur check on obtient en quelques millisecondes le résultat du validateur.
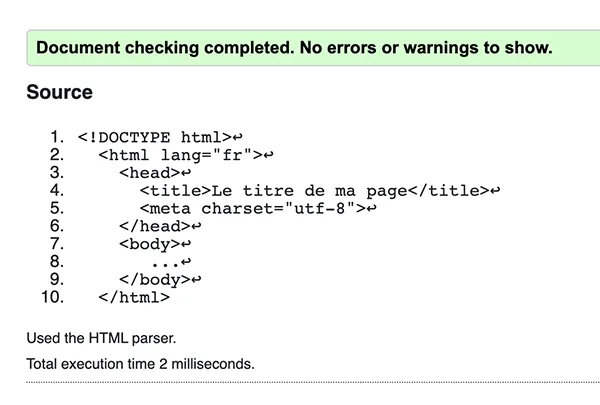
Le validateur nous indique que le document est conforme aux spécifications HTML5 et ne présente pas d’erreur ou d’avertissement. Voyons ce qui se passe dans ce cas en indiquant un attribut non reconnu sur l’élément <body>. Saisissons donc le même code en ajoutant <body attributMystere= »valeurMystere »>. Voilà le résultat du validateur :
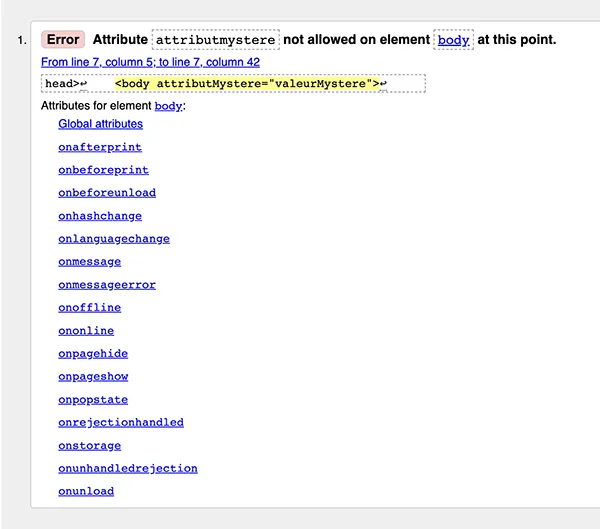
Comme l’on pouvait s’y attendre, le validateur lève une erreur là où on a introduit l’attribut mystère. Cet attribut n’étant pas reconnu comme valide pour cet élément, la ligne est marquée en erreur. De plus, dans son extrême bonté le validateur nous indique les attributs acceptés pour cet élément. Valider son document est une bonne pratique qu’il est important de réaliser, en particulier pour favoriser l’accessibilité au web pour tous.
Ce qu’il faut retenir sur la structure d’un document HTML
- Le W3C est l’organisation qui gère les standard des langages, spécifications et format de matériel du web. Dans le cas d’HTML c’est HTML5 qui est la dernière version actuelle et sur laquelle nous nous baserons uniquement à présent.
- Le !DOCTYPE est le type de document, il permet d’obliger le navigateur a appliquer les spécifications indiquées dans son DTD.
- L’élément <html> est l’élément racine d’un document web, il contient deux éléments essentiels <head> et <body>. Le premier contient l’en-tête du document, le second est le corps de celui-ci.
- On se sert du validateur W3C pour contrôler la conformité des documents HTML. Celui-ci lève des avertissements et des erreurs en fonction de la nature des écarts au standard rencontrés.
N’hésitez pas à poser vos questions en commentaire sur les structures de document en HTML ! Nous nous retrouvons bientôt pour continuer cette série sur les bases d’HTML5.



0 commentaires